High-Fidelity 3D Gaussian Splatting From
Sparse but Important Photographs Through Multi-View Diffusion Synthesis and 3D
Texture Consensus
Author: Eric Rubin and Dmitriy Pinskiy
Date: November 2025
Abstract
Capturing high-quality 3D assets traditionally requires dozens to hundreds of photographs. However, in many practical scenarios—such as e-commerce product visualization or design prototyping—it is often possible to obtain only a few high-fidelity “hero views.” The challenge is to reconstruct a full 3D Gaussian Splatting (3DGS) model that preserves precision in these important views while ensuring self-consistent appearance across all unseen or lightly constrained regions of the object.
This paper introduces a reconstruction framework that leverages a diffusion-based image synthesizer to generate missing views and a surface-level 3D texture consensus mechanism to guarantee global consistency. Unlike multi-view diffusion or video-based consistency approaches, this method does not require training new diffusion models. It delegates consistency enforcement to a principled 3D collapsing mechanism that merges real and synthetic data into a unified 3D appearance field.
The result is a stable, scalable pipeline capable of producing clean, consistent 3DGS assets from as few as 2–5 real images, while preserving the exact appearance characteristics captured in the prioritized photographs.
1. Introduction
High-quality 3D reconstruction is central to applications in digital commerce, augmented reality, robotics, and creative design. While 3D Gaussian Splatting (3DGS) has emerged as a powerful representation for real-time rendering and photorealistic appearance modeling, its performance relies heavily on the density and coverage of input photographs.
Unfortunately, in many workflows—especially product photography—capturing a complete, uniform dataset is impractical. Instead, photographers usually capture:
●
A small set of hero views
that define the product’s most important aesthetic characteristics.
●
Few or no images of less visible
or physically inaccessible surfaces.
Conventional 3DGS reconstruction from sparse views suffers from:
●
Missing regions or holes
●
Inconsistent coloring
●
Hallucinated surfaces that do not
match real-view constraints
This paper addresses these limitations by introducing an approach that augments sparse capture with diffusion-generated views, followed by a mathematically principled 3D consistency collapse.
2. Motivation and Requirements
2.1 Importance of High-Fidelity Views
We assume that:
●
Certain views contain essential
details (logos, gemstones, unique patterns, materials).
●
These views must be reconstructed
with maximum fidelity.
●
Any deviation from these real
views is unacceptable.
2.2 Unseen Regions Require Consistency but Not Accuracy
For unseen or occluded surfaces—such as the interior of a ring or back of a dress—there is no real imagery. In these regions:
●
Accuracy is not possible, nor required.
●
Consistency is essential, so the rendered object does not flicker or exhibit contradictory
textures across angles.
In other words:
Important views require precision;
the rest of the object requires coherence.
3. Overview: Diffusion Augmentation + 3D Texture Consensus
Our method comprises three major components:
- Sparse Capture and Initial 3DGS Reconstruction
- Diffusion-Based
Multi-View Image Generation
- Surface-Level 3D Texture Collapse to Enforce Self-Consistency
These stages are illustrated conceptually below.
4. Stage 1 — Sparse Photographic Capture and Initial 3DGS
A set of 2–5 real images is captured under controlled conditions, representing the most critical views. From these:
●
Camera poses are estimated using
COLMAP or similar SfM tools.
●
A coarse but structurally stable
3DGS model is trained.
This initial 3DGS is incomplete but provides:
●
Approximate geometry/splat layout
●
Viewing directions
●
The ability to render proxy
views from any angle
These proxies serve as conditioning inputs for the next step.
5. Stage 2 — Diffusion-Based Multi-View Image Generation
5.1 Purpose of the Diffusion Model
The diffusion model (e.g., Stable Diffusion with ControlNet, or an IP-Adapter conditioned on hero views) is not required to:
●
Reproduce the exact product,
●
Maintain global consistency across
all view angles,
●
Respect fine details on unseen
surfaces.
Instead, its purpose is:
To hallucinate plausible appearance
for missing views while remaining stylistically aligned with the real photos.
5.2 Conditioning Mechanisms
The diffusion model may be conditioned on:
●
Proxy renders of the coarse 3DGS
●
Depth maps, normal maps, and masks
●
A reference “hero view” image
●
Style prompts or textual grounding
This ensures the synthesized images are:
●
Material-consistent
●
Angle-appropriate
●
Compatible with the visual
signature of the real photographs
Even if generated images exhibit inconsistencies across angles, this is acceptable — they are not final.
5.3 Coverage
Dozens or hundreds of synthetic views are generated in a dense orbit around the object, guaranteeing full surface coverage.
6. Stage 3 — 3D Texture Consensus (Surface-Level Collapse)
This is the core contribution of the approach and the strongest differentiator from video-like diffusion or multi-view diffusion training.
6.1 Key Insight
While diffusion models do not naturally enforce multi-view consistency, 3DGS does.
By projecting all generated views back into the 3D splats and averaging their contributions, we enforce a unified appearance model.
6.2 Process Overview
For each generated or real view:
- Render the coarse 3DGS and record:
○
For each pixel: which splat
(surface point) contributed most.
- For the
corresponding synthetic (or real) image:
○
Sample the color at each pixel.
○
Assign that color to the splat
observed.
This produces, for each splat sss:
Cs={ci,p∣p in view i observes splat s}}
6.3 Weighted Consensus
To preserve accuracy in hero views, we use a weighted aggregation:
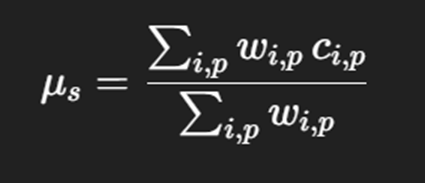
where:
●
wi,p≫1 for pixels from important real photos
●
Wi,p≈1 for synthetic images
This ensures:
●
Real photos dominate in regions they cover
●
Generated photos fill in the rest
consistently
6.4 Finalizing the 3DGS
Each splat receives a final color:
color(s)=μs\text{color}(s) = \mu_scolor(s)=μs
This yields a globally consistent and complete 3DGS model, regardless of inconsistencies in the input synthetic images.
7. Why This Works
7.1 Decoupling Fidelity from Consistency
Traditional multi-view reconstruction requires many accurate photographs. Here, we collapse two responsibilities:
●
Diffusion provides visual diversity and plausible missing data
●
3DGS collapse provides global consistency and hard guarantees
This allows sparse input capture without sacrificing stability.
7.2 Precision Where It Matters
The weighting scheme ensures that splats observed in hero photos remain exactly anchored to real data.
7.3 Consistency Everywhere Else
Even if synthetic images disagree on certain areas:
●
Their disagreement is averaged out
●
The 3DGS learns a single stable
appearance for each point
●
No flickering or multi-texture
artifacts appear during rendering
7.4 No Need for Multi-View Diffusion Training
The pipeline works with off-the-shelf SD models.
8. Applications
8.1 E-Commerce Visualization
●
Reconstruct a complete 3D model
from 3–4 studio photographs
●
Guarantee accuracy in hero shots
(front-facing product photos)
8.2 Jewelry, Fashion, and Glassware
●
These items often have occluded
regions
●
Diffusion can hallucinate
consistent backside materials
8.3 Design Iteration
●
Change
the hero view image slightly → generate a new 3D model with consistent
materials
8.4 3D for Marketing
●
Consistent 360° turntables from
minimal photographic input
9. Comparison to Alternative Approaches
|
Approach |
Pros |
Cons |
|
(This paper) 3D Texture Consensus |
Hard consistency guarantee; preserves real-photo fidelity; no SD training |
Synthetic images may be low-quality individually |
|
Video-like SD w/ global attention |
Higher detail consistency pre-collapse |
Requires model training; no hard guarantees |
|
Multi-view diffusion (research) |
Consistent generation |
Hard to train; not commercially ready |
|
Pure 2D diffusion → direct 3D reconstruction |
Poor consistency; flickering |
Does not enforce surface binding |
This approach uniquely combines the strengths of SD with the enforcement power of a 3D surface representation.
10. Limitations
●
Diffusion hallucinations may
produce unrealistic or unwanted details in unseen regions (but remain
consistent after collapse).
●
Requires an initial coarse 3DGS or mesh to know which splats correspond to which
pixels.
●
Performance depends on coverage
and diversity of generated synthetic views.
11. Conclusion
This paper presents a practical, robust, and high-fidelity method for generating 3D Gaussian Splatting models from a sparse set of important photographs. By combining diffusion-based view synthesis with a surface-level consensus mechanism in 3D, we achieve:
●
Perfect precision where it
matters
●
Full-object consistency
everywhere
●
Operational simplicity using
existing models
●
High-quality 3D reconstruction
from minimal input
This approach redefines what is possible in minimal-capture 3D reconstruction and provides an immediately deployable solution for high-value industries such as product visualization, digital commerce, and creative design.